Vurderinger ved anskaffelse av IT-tjenester og -systemer
Som systemeier, prosjektleder, innkjøper og applikasjonsforvalter er det flere aspekter ved integrasjonsarktitekturen man bør tenke gjennom før produkt eller leverandør velges. Her diskuteres punkter ved integrasjoner som er verdt å ta med seg. Det meste handler om kost/nytte-vurderinger, som er ulik for hver IT-tjeneste.
Moderne og gammeldags programvare
Det viktigste først: Når du kjøper ferdig programvare, såkalt hyllevare, må du ikke falle for fristelsen til å kjøpe tjenester for å tilpasse programvaren til organisasjonen. Dette er som oftest det dyreste valget, siden tilpasninger av hyllevare ofte gire store merkostnader. Tilpass heller organisasjonens prosesser etter programvaren, med mindre det er del av primærvirksomheten eller et strategisk valg å følge egne prosesser. For administrative prosesser er det ofte bedre å tilpasse seg tjenesten, mens det innen forskning og utdanning er en vanskeligere vurdering.
Når du som systemeier anskaffer programvare, så er det gjerne programvare en bruker, et menneske, skal sitte å jobbe i. Med integrasjonsøyne er det da i hovedsak fire forhold som må vurderes:
1. Provisjonering
Det er vanlig at tjenester trenger provisjonering av informasjon, som brukerkontoer. Nesten alle kjøpte webapplikasjoner med brukerinnlogging havner i denne kategorien.
Eldre typer teknologi benytter gjerne katalogtjenester, som AD eller LDAP. Dette er ofte rimelig å implementere, siden tjenesten har dette ferdig satt opp, og katalogen er allerede på plass. Ulempene er blant annet at du er tvungen til å bruke de dataene som er tilgjengelige i katalogen, og det er vanskeligere å ha oversikt over hvem som har tilgang. Det er heller ikke så mange begrensninger på hvem som kan se informasjonen i katalogen - spesielt i AD har alle tilgang til alle data - så du ønsker ikke eksponere beskyttelsesverdige data i katalogen.
Vi er opptatt av om tjenesten kan oppdateres i sanntid eller ikke. Her snakker vi da om den kan få eller avgi informasjon fra/til andre IT-tjenester kontinuerlig eller periodisk (for eksempel en gang i døgnet). Provisjonering kan også skje manuelt ved at man taster inn navn, adresse eller lignende.
Programvare som bygger en brukerkonto/-profil under første innlogging kalles "Just in Time provisjonering" (JIT). Disse henter ofte data om brukeren gjennom Feide-påloggingen (OpenID Connect (OIDC) eller SAML), men kan også få utfyllende detaljer fra et API i påloggingsprosessen (for eksempel ved bruk av OAuth).
Integrasjonsmessig kan JIT virke fordelaktig over vanlig provisjonering, men også her er det fallgruver. JIT-tjenester bygger gjerne en tynn profil, og forventer at brukeren registerer resten av sine data selv.
2. Integrasjonsteknologi
Filoverføringer og spørringer direkte mot databasen (SQL) regnes som gammeldags ("legacy"), men også integrasjon via Web Services (WS) kan gjøres på avleggs måter. Vanligvis foretrekker vi en retning innen Web services som kalles RESTful. Denne retningen har sin styrke i å være intuitiv, man kan lete seg frem til data man trenger, og behøver liten eller ingen kunnskap om kommandoord eller argumenter. Se design av API for mer detaljer.
I dag er det ofte REST som er bransjestandarden i bruk av WS, da den er enkel å bruke. Eldre WS-varianter er SOAP, men den er lite intuitiv, ofte proprietær, har høy inngangsterskel og liten gjenbruksverdi, og er derfor ikke anbefalt å bruke mellom tjenester.
Det kommer også nye WS-varianter, for eksempel GraphQL og gRPC, som kan ha sine styrker og fordeler. De må likevel vurderes før de akspeteres - er de utbredte nok til å være en ny bransjestandard, eller er det fare for lock in? Mister du noen av fordelen som den eldre varianten har? Blir det enklere eller mer komplisert å integrere? Ofte ønsker vi å prioritere at det er enkelt å integrere mot WS-varianten, enn at WS-varianten er rask og effektiv.
Heller ikke REST er uten ulemper, og dette har vi samlet i et eget dokument.
Sanntidsoppdateringer er i dag ikke godt nok støttet i WS i seg selv, så i fellestjenesten for datadeling tilbyr vi å bruke en meldingskø (MQ) for dette. Dette håndteres då uavhengig av API-et. Det kan godt komme sanntidsoppdateringer gjennom WS i fremtiden som kan dekke bruksmønster godt nok.
3. Galvanisk skille
Et tredje kriterie man kan rette seg etter for å bedømme hvor moderne en IT-tjeneste/programvare er, er om man gjør innlogging i operativsystemet, eller i applikasjonen. Om operativsystemet vet hvem du er eller ikke, kaller vi et galvanisk skille.
Forenklet sagt: Styr unna tjenester som gjør innlogging i operativsystemet.
4. Trelagsarkitektur
Trelagsarkitektur innebærer at man kan benytte (helst valgfri) funksjonalitet fra en IT-tjeneste i en annen. Som regel er det ønskelig med API mellom lagene/funksjonaliteten.
Et eksempel er at en portal for studenter kan hente data fra ett API for å hente hvilke emner studenten tar, og ett API for å vise dagens forelesninger. I tillegg kan portalen gi mulighet for å reservere et kollokvierom. Alt dette kan gjøres direkte i portalen, uten å måtte gå innom andre tjenester/nettsider, fordi portalen kan gjøre dette gjennom de andre tjenestenes API.
Oppsummering
Kort oppsummert gir dette en matrise med noen stikkord som kan si oss noe om hvor moderne en applikasjon er, spesielt med henhold til om den er tiltenkt store brukermasser med homogene behov. De fleste applikasjoner har trekk fra både raden 'Moderne' og raden 'Gammeldags'.
| Provisjonert | API | Autentisering | Applikasjons-oppbygning | |
|---|---|---|---|---|
| Moderne | Sanntidsoppdatering | REST og meldingskø | SAML, OIDC, Oauth | Løst koblet trelagsarkitektur (med hendelser) |
| Gammeldags | Batch (eller manuell) | SOAP, filoverføring, systembruker, SQL, RSS, "REST-rpc" | Katalogtjenester, som AD og LDAP, til autentisering og/eller autorisasjon | Tolagsarkitektur, eller programvare med tette koblinger |
Web Services
Web Services (WS) er en type API (integrasjonsgrensesnitt). Det er noe programvare benytter for å sende informasjon mellom seg, og ikke direkte mellom bruker og programvare. Vi som driver med integrasjonsarkitektur liker altså WS. WS er de facto standard for utveksling av informasjon på internett i dag.
Web service er riktignok en sekkebetegnelse. Når man vurderer programvare er det ikke nok at leverandøren forsikrer om at programvaren har web services. Det kan ennå være mange hindringer i veien: Lisenser, dokumentasjon, spesialkompetanse, proprietære formater osv. Kan API-et faktisk brukes av konsumenter?
Sanntidsoppdatering
Det finnes flere sanntidsteknologier, men den vi har valgt i fellestjenesten for datadeling (IntArk) bruker Meldingskø (MQ). Illustrasjonen under viser informasjonsflyten. Teknisk implementasjon krever langt flere komponenter.
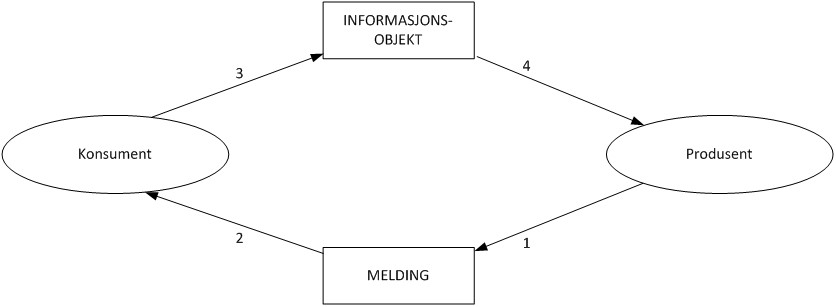
Hver gang det skjer en endring i kildedataene hos datatilbyder (produsent), sender datatilbyder en notifikasjon til meldingskøen, men lenke til informasjonen som har blitt endret (vanligvis tjenestens API). Meldingskøen tar seg av å sende denne notifikasjonen videre til alle konsumenter som er interesserte. Konsumenten leser notifikasjonen, vurderer om det er relevant, henter data fra API-et, og gjør nødvendige oppdateringer hos seg.
Med meldingskø kan mange konsumenter få den samme meldingen. Alle som har en meldingskø kan få oppdatert sine data umiddelbart, når data endres i datakilden. Meldingskøen holder (for hver kø) på meldingen til køens konsument har hentet meldingen. Verdien til meldingskøer er altså lett å se: Alle IT-tjenester (som benytter tjenesten) vil ha konsistente data umiddelbart.
Les mer om sanntidsoppdatering
Masterdata, delte data og verdikjeder
Et spørsmål som reises når man forteller om meldingskø er om man da kan skifte sine data i et hvilket som helst system, og så vil dette reflekteres i alle system. Svaret er at dette er kompleksitet vi ikke klarer å håndtere. Derimot kan man gjøre det fra et hvilket som helst presentasjonslag, som mobil-app eller nettleser, så lenge de benytter samme datalager i bakgrunnen. For å håndtere kompleksiteten må en og bare en IT-tjeneste være autoritativt kildesystem hos institusjonen. Det er en bestemmelse som gjøres utenfor IT. Man bestemmer at dersom data ikke er like i to datakilder, er det den ene kilden som gjelder, uavhengig av hvor data ble endret sist.
Hvilke datakilder som er autoritative for hvilke data kan variere, men det må være bestemt på forhånd. De data en IT-tjeneste er autoritative for, kalles autoritative data, eller kildedata. Man skal helst hente data fra autoritativ kilde, men dersom dette ikke er hensiktsmessig, skal dataene ikke endres på veien. Typiske eksempler er programvare som henter data fra katalogtjenester som AD og LDAP.
Ved anskaffelser må det være tydelig på forhånd hvilke data tjenesten som anskaffes skal være autoritativ for, og hvilke data som skal hentes fra andre kilder. De fleste IT-tjenester har langt mer autoritative data enn det de andre konsumentene har behov for. Ofte benyttes derfor begrepet masterdata om dataen tjenesten er autoritativ for og deler med andre tjenester. Men hva man deler fra dag én, og hva som skal deles i fremtiden, er ikke alltid lett å forutsi.
Les mer om masterdata og verdikjeder
Retrofit
Hva om min foretrukne skytjeneste eller programvare ikke har MQ og RESTful web services? Hva om den snakker SOAP og RSS? Benytter systembruker?
Vi gjør iblant grep for å få gammel teknologi til å fungere med ny teknologi. Et slikt grep kalles en retrofit. Ofte gjøres det ved at noen implementerer en mikrotjeneste som oversetter. Dette gjør at vi har et større utvalg av IT-tjenester å velge mellom.
En retrofit har en kostnad, både i utvikling og videre drift og forvaltning. Dette må med i vurderingen av tjenester.
For mange større tjenester finnes det allerede mikrotjenester som kanskje kan gjenbrukes. For eksempel foran Canvas, Zoom og Exchange.