Hendelsesbasert provisjonering
Detaljer om integrasjonsmønsteret kalt "hendelsesbasert provisjonering".
Dette integrasjonsmønsteret anbefales for tjenester som trenger å provisjoneres, og som har nytte av å bli raskt oppdatert med nye data. For eksempel når brukerne forventer at data er oppdaterte tilnærmet umiddelbart, og ikke dagen etterpå.
Mønsteret fungerer ved at datatilbyder tilbyr sine data via et API, og sender ut notifikasjoner (tynne meldinger) når det skjer endringer i dataene som tilbys. Konsumentene lytter etter notifikasjoner fra datatilbyder, og henter relevante data fra API-et.
Fellestjenesten tar seg av å distribuere notifikasjonene fra datatilbyder til alle konsumenter som er interesserte. Datatilbyder trenger da bare å forholde seg til meldingskøen og ikke hver enkelt konsument.
Hvorfor dette mønsteret?
Dette mønsteret gjør at mindre data trenger å overføres, og at konsumentene kan bli oppdatert umiddelbart. Dette uten behov for å hente absolutt alle data fra tilbyderen, eller at datatilbyder må selv dytte data ut til hver enkelt konsument.
Tradisjonelt har man brukt tunge, filbaserte batch-oppdateringer for å provisjonere tjenester. Dette er ikke en effektiv måte å integrere på, fordi produsenten må samle og overføre komplette datasett, og konsumenten må sammenligne det komplette datasettet i hver runde. Det hendelsesbaserte mønsteret effektiviserer integrasjonen, og gjør at bare nødvendige data kan overføres, raskere.
Mønsteret er ikke designet for tjenester som trenger historiske data eller trenger å "spille av" tidligere endringer. Slike tjenester vil fort kunne ha behov for mer komplisert funksjonalitet, enten at datatilbyder eller konsument lagrer slik historikk selv, eller mer avansert mellomvare enn enkle meldingskøer.
Bruken av meldingskøer for å håndtere notifikasjoner om endringer er valgt av tekniske grunner. Meldingskøer er effektive og lite kompliserte, og gjør at datatilbyder slipper å måtte forholde seg til hver enkelt konsument i utsendingen. Alternative metoder, som HTTP-kall eller websockets, har ikke vært modne nok og har ført til mer kompleksitet hos datatilbyder, og har derfor blitt valgt bort. Tekniske endringer i fremtiden kan endre på denne anbefalingen.
Teknisk flyt
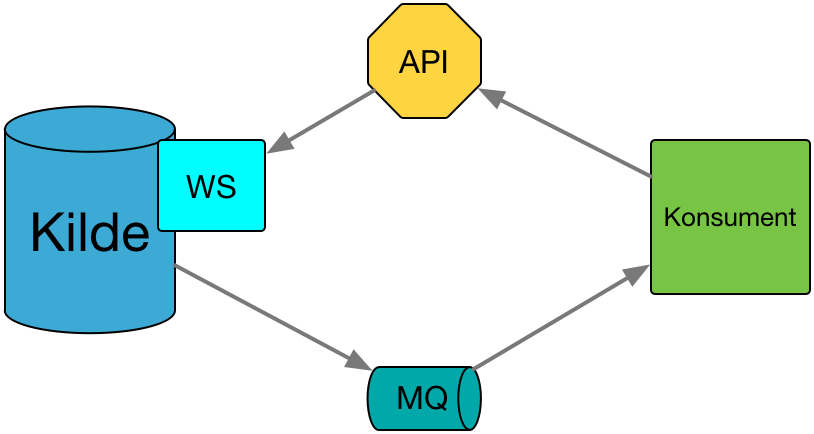
En typisk flyt med dette integrasjonsmønsteret:
- Datatilbyder får endret data om en entitet, for eksempel fordi en saksbehandler gjør endringer.
- Datatilbyder sender ut en notifikasjon til meldingskø-tjenesten, RabbitMQ, om at noe har skjedd. Notifikasjonen inneholder lite data, annet enn hvilken entitet det gjelder.
- Meldingskø-tjenesten tar i mot notifikasjonen og distribuerer den videre til alle konsumenter som abonnerer på dataene de gjelder.
- Konsumenten mottar notifikasjonen, og ser om den er relevant.
- Konsumenten henter ut data fra kildesystemet sitt API.
- Konsumenten oppdaterer sine interne data.
Hvis konsumenten selv er tilbyder av andre kildedata som blir oppdatert basert på dette, vil konsumenten bytte rolle til datatilbyder og gå gjennom samme prosessen. Et eksempel på dette er at en ansatt får endret sitt navn i personalsystemet, som gjør at e-posttjenesten endrer primær e-postadresse, som gjør at andre konsumenter endrer sine data. I dette tilfellet kan også personalsystemet være en konsument og oppdatere den ansatte sin e-postadresse indirekte grunnet navneendringen. Merk at e-posttjenesten skal ikke sende ut notifikasjoner om at navn er endret, siden det er personalsystemets ansvar, men bare for endret e-postadresse.
Et eksempel fra flyten over:
- En saksbehandler endrer mobilnummeret til en ansatt i personalsystemet (datatilbyderen).
- Personalsystemet sender notifikasjonen "person-objekt med id 123 er endret" til RabbitMQ.
- RabbitMQ sender notifikasjonen videre til konsumentene som abonnerer på de. En av disse kan være et CMS med personpresentasjoner.
- CMS mottar notifikasjon om at person 123 er endret. CMS ser at denne personen er registrert hos seg, og trenger derfor å reagere.
- CMS kaller på API-et til tjenesten, via API manager, og henter ut data om personen. Avhengig av granulariteten til datatilbyder, vil CMS enten få returnert mobilnummeret eller flere personopplysninger.
- CMS sammenlikner personopplysningene, og oppdatere data som er endret.
Når bør dette brukes?
Dette mønsteret passer når du trenger å provisjonere et endesystem med kildedata fra en tilbyder, uten at sluttbrukeren er involvert.
Dette mønsteret bør brukes når noen forventer at data er tilgjengelig tilnærmet umiddelbart, eller når fortløpende oppdateringer gir en bedre brukeropplevelse.
Det er ofte en kost-nytte-vurdering om raskt oppdaterte data gir nok gevinster til å veie opp for kostnadene. Ofte blir gevinstene undervurderte, da indirekte kostnader ikke blir inkludert - når data blir raskt oppdaterte øker tilliten til de og de blir brukt mer og av flere konsumenter.
Fordeler
-
Data blir oppdatert raskere i mange systemer - "tilnærmet umiddelbart". Dette gir ofte en bedre brukeropplevelse, og mer tillit til dataene og tjenesten.
-
Mye mindre ressurskrevende enn det eldre mønsteret der du henter alle data fra kilden, og oppdaterer konsumenten.
Ulemper
-
Passer best for system-til-system-integrasjoner.
-
Har du veldig mange konsumenter vil det sette høyere krav til ytelsen hos datatilbyder. Dette kan kompenseres ved for eksempel caching i API manager.
-
Å implementere notifikasjonsutsending hos datatilbyder kan være krevende å implementere. Det kan også være ukjent teknologi for mange utviklere.
-
Mønsteret koster mer å implementere enn en gammeldags fullsynk.
Eksempler
-
DFØ sine API støtter utsending av hendelser når det skjer endringer i deres API. Overføring av notifikasjoner fra DFØ til din institusjon må settes opp - ta kontakt.
-
Flere IGA-løsninger, som Rapid Identity og Cerebrum, støtter utsending av hendelser når det skjer endringer på brukerkontoer og grupper.
Flere og flere tjenester i sektoren støtter utsending av notifikasjoner ved endringer i sine data, spesielt de som utvikles av sektoren selv.
Fallgruver
Datatilbyder skal bare sende ut notifikasjoner når data faktisk er endret hos seg selv, og ikke sende ut notifikasjoner bare fordi tjenesten har mottatt notifikasjoner fra andre. Falske positive notifikasjoner vil føre til mer ressursbruk, siden det kan føre til unødvendige API-oppslag fra konsumenter. I verste fall vil du kunne få evige meldingsløkker hvis to systemer som snakker sammen gjør samme feilen - de vil sende samme notifikasjonen fram og tilbake, uten stopp.
Notifikasjonene er tynne - inneholder få data - men de vil likevel kunne inneholde personopplysninger: en identifikator til en person eller til data som tilhører en enkelt person. Notifikasjonene må derfor behandles som personopplysninger. Fordelen med at notifikasjonene er tynne, er at du reduserer risikoen for at de inneholder personopplysninger som krever ekstraordinære tiltak, for eksempel helseopplysninger, da dette skal beskyttes bak datatilbyders API.